Wij leggen uit waarom data preparation een essentieel onderdeel is van machine learning!
De masterclass ‘Data Science in de zorg’ stond afgelopen week in het teken van data preparation. Met als doel om de data te bewerken tot geschikte input voor een machine learning-algoritme. Maar hoe doe je dit? En wat is daar allemaal voor nodig? Aan de hand van 2 zorgcases leggen wij uit hoe het proces van data preparation verloopt om tot een succesvol machine learning-model te komen.
Data preparation kan je omschrijven als het ontsluiten, opschonen en koppelen van data. Dit komt neer op het voorbereiden van onbewerkte datagegevens zodat ze eenvoudig gebruikt kunnen worden voor machine learning software. Om tot bruikbare uitkomsten te komen doorlopen we doorgaans een aantal vaste stappen.
Het doel van data preparation is om ‘tabellen’ te creëren met data die de businesscases van de zorginstelling kunnen ondersteunen. Het is noodzakelijk om keuzes te maken op basis van databeschikbaarheid (toegankelijkheid) om zo tot een kansrijke en uiteindelijk succesvolle zorgcase te komen. Andere onderdelen die in het geval van machine learning een rol spelen zijn:
- Input zorgprofessional: De zorgprofessional brengt domeinkennis in en denkt mee over welke zorginhoudelijke actie ingezet kan worden.
- Data verkenning: Alle relevante data verzamelen, inbrengen en betekenis geven. Is die kwalitatief voldoende of missen er nog zaken? Het kan gaan om interne zorgdata of externe factoren.
- Voorspelling: Hier wordt er bepaald wat er vanuit de businesscase wordt geanalyseerd. Zo kan de vraag zijn of een zorginstelling een voorspelling wil doen over een patiënt of een behandelcontact.
- Moment van voorspellen: Het gaat om wanneer in het behandeltraject (begin, midden, eind) de voorspelling nodig of realiseerbaar is.
- Actie: Welke actie je wilt koppelen aan deze uitkomsten? Wat gaat de zorginstelling doen met de voorspelling?
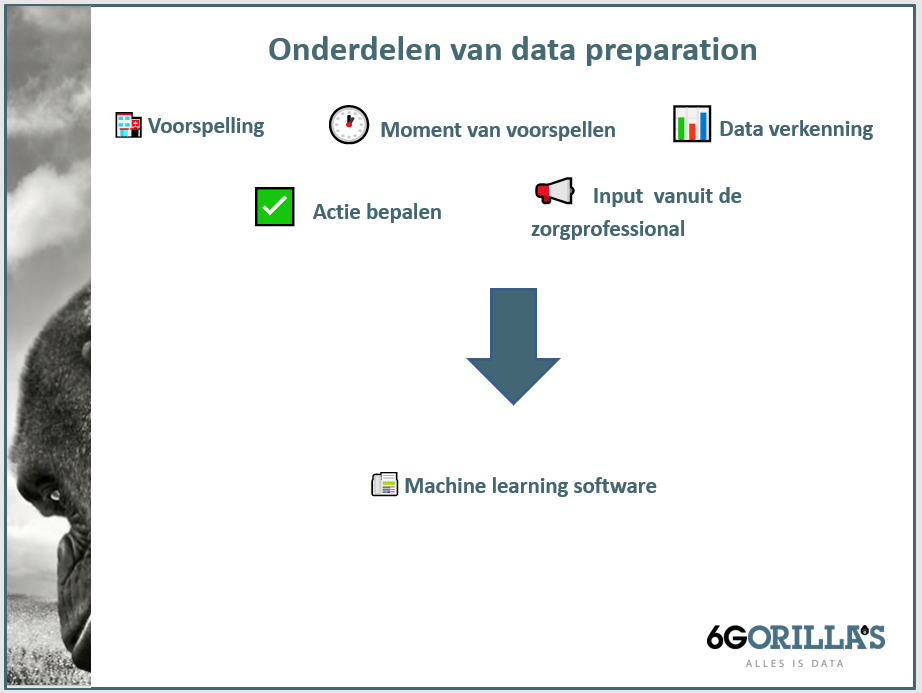
Wanneer deze onderdelen in acht worden genomen verhoogd dit de kans op een succesvolle machine learning-toepassing. Waarbij machine learning slechts een middel is om een bepaald doel te bereiken en geen doel op zich.
Hoe twee zorginstellingen de data inbrengen voor machine learning
Het proces van input voor datasets van machine learning lichten we toe aan twee zorgcases.
🏥 Zorginstelling 1 (geestelijke gezondheidszorg) heeft als zorgcase: het inschatten van hoe groot de kans is dat een patiënt uitvalt in het zorgtraject.
Deze kans willen ze per patiënt voorspellen. Om de aantal weken wordt er ingeschat welke patiënten een vergrote kans hebben om uit te vallen in het zorgtraject. Om de uitval tegen te gaan kiest deze zorginstelling voor interventie; door eerder contact op te nemen met de patiënt of een aanpassing door te voeren in het behandelplan. Om tot de voorspelling over te gaan maken zij gebruik van demografische gegevens, diagnoses en brongegevens.
🏥 Zorginstelling 2 (geestelijke gezondheidszorg) heeft als zorgcase: door de voorspelling van tekst signaleren zij eerder in het traject of een cliënt een langere periode dan 365 dagen in zorg blijft. Zodat, waar nodig, het hulpverleningstraject wordt bijgesteld.
De voorspelling vindt plaats per cliënt. Met de data willen zij na 180 dagen behandelen een inschatting maken welke cliënten langer dan 365 dagen in de zorg blijven. Zij passen het hulpverleningstraject aan met passende acties voor de cliënt. De meest gebruikte data is aantal types zorg, aantal minuten zorg, hoeveelheid activiteiten, aantal hulpverleners en text mining.
Van datasets naar modeling
De volgende sessie richt zich op modeling. Tijdens deze fase proberen de zorginstellingen verschillende modellen uit om te zoeken naar het model dat de beste samenhang vindt tussen de inputgegevens en de uitkomst die het probeert te voorspellen. De manier van benaderen bij de modellen verschilt, waardoor het ene model net weer wat beter in staat kan zijn om een uitkomst te voorspellen dan het andere model. De zorginstellingen worden ondersteund door 6Gorilla’s om scripts op te stellen om tot de juiste modellen te komen.
6Gorilla’s Masterclasses ‘Data Science in de zorg’
Wij verzorgen een tiendelige masterclass ‘Datascience in de zorg’ voor verschillende opdrachtgevers uit de zorg. Datascientist Joran Lokkerbol verkent samen met de zorgorganisaties hoe zij data kunnen inzetten om de effectiviteit van de zorg te vergroten. Mocht je vragen hebben over de inhoud van de masterclasses of over 6G; neem dan contact op.
Handout ‘How to learn machine learning?’
In 6 stappen leer jij Data Science toepassen in jouw zorgorganisatie!
Wil jij aan de slag met data science in jouw organisatie? Aan de hand van het CRISP-DM model laten wij zien hoe je in 6 stappen met data science kunt starten! Als voorbeeld hanteren we hoe Ravian Wettstein en Jeroen Kroesen van ADHDcentraal aan de slag zijn gegaan met hun eigen machine learning project.
De Handout ‘How to learn machine learning?’ bevat de volgende inhoud:
✔ Business & Data understanding
✔ Data Preparation & Modeling
✔ Evaluation & deployment![]()